Data Engineering
Vor der Datenanalyse bzw. -modellierung müssen Ihre Daten aufbereitet werden. Dazu gehören u.A. die…
Datenauswahl
Selektion und Bereitstellung der für die Analyse / Modellierung notwendigen Daten.
Datenbereinigung
Durchführung von Fehlererkennungs- bzw. Fehlerkorrekturschritten für beispielsweise fehlerhafte Daten / Datenpunkte
Datenstandardisierung
Vereinheitlichung von Eingabedaten der ML-Tools, um das Risiko fehlerhafter Eingabedaten zu reduzieren.
Mit unseren Data Engineering Tools stellen wir zuverlässige Datenströme aus unterschiedlichsten Quellen bereit und wir stellen die nötige Infrastruktur für den optimalen Workflow Ihres Data Science Projekts her:
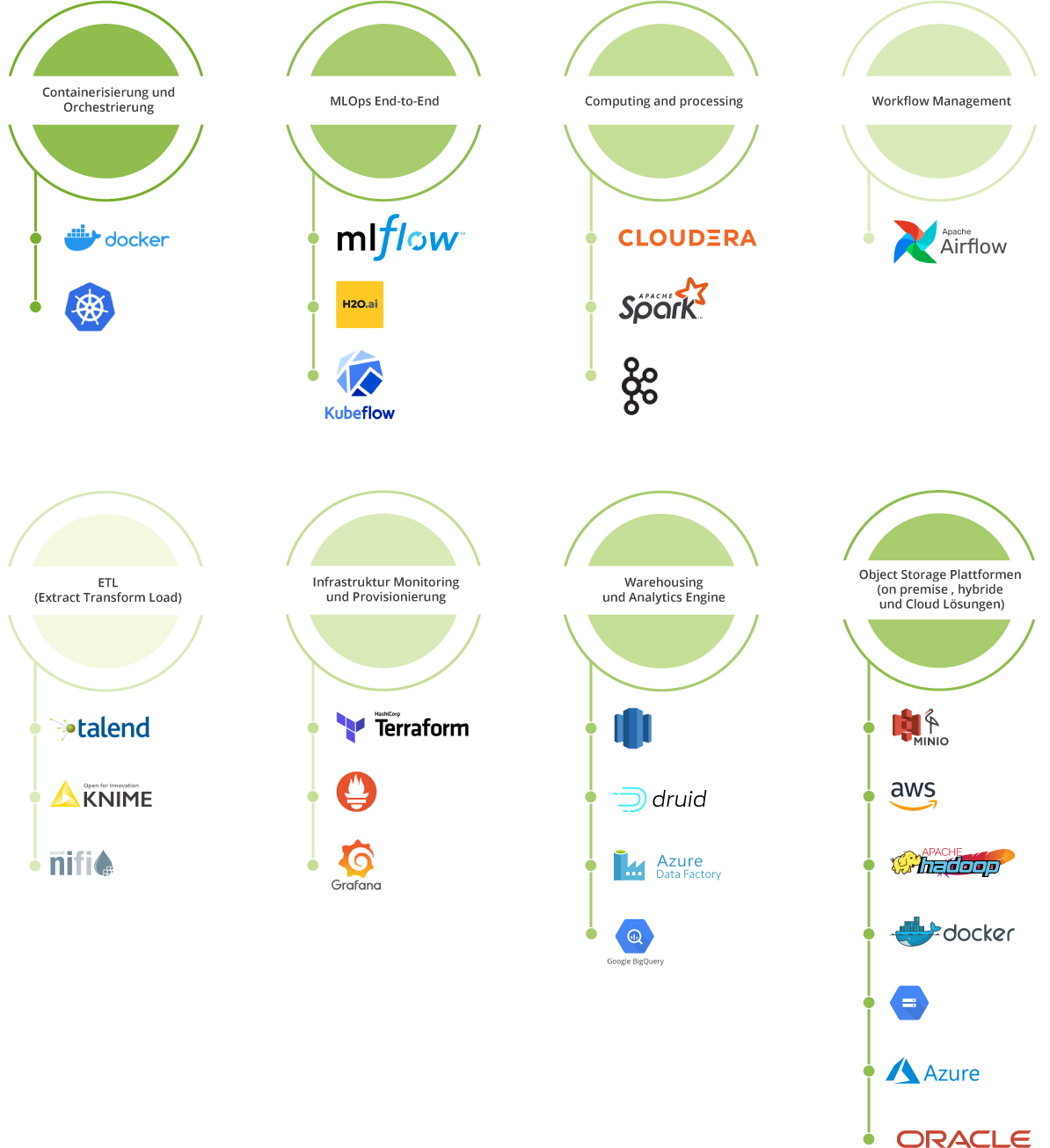
In unserem Team beschäftigen wir uns ständig mit den neuesten Technologien, um maßgeschneiderte Lösungen für möglichst viele Use Cases in modernen datengetriebenen Projekten zu bieten. In folgenden Medium-Artikeln zeigen wir Schritt für Schritt mögliche Umsetzungen auf Basis unserer technischen Expertise:
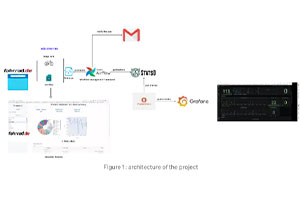
Data Pipelines with Monitoring Tools
Schritt für Schritt Anleitung für den Aufbau eines Data Stacks
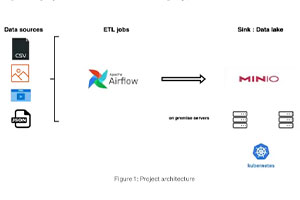
On Premise Data Lake
Erstellung eines Storage Layers für jedes Data-Science-Projekt in einer On-Premise-Konfiguration
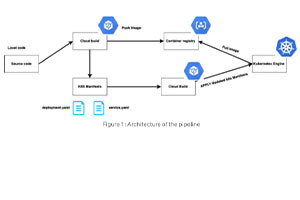
Computer Vision from Scratch
Bau eines CNN-Modells mit Tensorflow und Keras, um Krankheiten in Blättern festzustellen
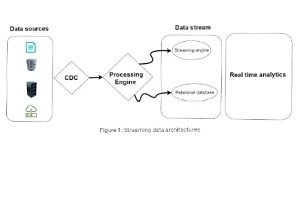
Change Data Capture using Debzium Kafka
Nutzung von Debezium, um Änderungen und Transaktionen bei der Nutzung von Databases
Jetzt Kontakt aufnehmen
Sie möchten die Vorteile von KI-Lösungen nutzen, um Ihr Unternehmen weiter zu bringen?
Kommen Sie auf uns zu – wir beraten Sie gerne über Möglichkeiten und Anforderungen, damit Sie so schnell wie möglich auf die Überholspur kommen!
